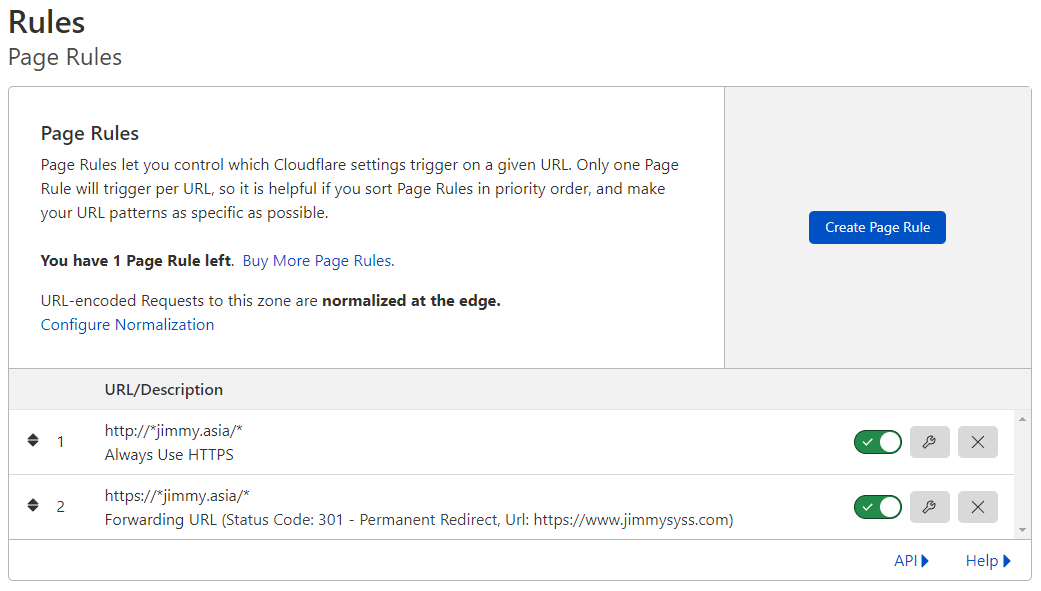
I use a pre-crafted image from my Cloud Provider, so need to handle for iptables rules first.
sudo sh -c "iptables -I INPUT -p tcp -m tcp --dport 80 -j ACCEPT && iptables -I INPUT -p tcp -m tcp --dport 443 -j ACCEPT && service iptables save"
1. GRUB
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash nopti noibrs noibpb nospec nospectre_v2 nospec_store_bypass_disable mitigations=off"
2. FSTAB
/etc/fstab
LABEL=cloudimg-rootfs / ext4 noatime,defaults 0 1
3. SYSCTRL
/etc/sysctl.conf
vm.swappiness = 1
vm.dirty_background_ratio = 10
vm.dirty_ratio = 5
fs.inotify.max_user_watches = 524288
net.ipv6.conf.all.disable_ipv6 = 1
net.ipv6.conf.default.disable_ipv6 = 1
net.ipv6.conf.lo.disable_ipv6 = 1
sudo crontab -e
@reboot /sbin/sysctl --load=/etc/sysctl.conf
4. IPTables
/etc/iptables.conf
-A INPUT -p tcp -m state --state NEW -m tcp --dport 80 -j ACCEPT
-A INPUT -p tcp -m state --state NEW -m tcp --dport 443 -j ACCEPT
5. MariaDB
sudo apt-get install software-properties-common dirmngr apt-transport-https
sudo apt-key adv --fetch-keys 'https://mariadb.org/mariadb_release_signing_key.asc'
sudo add-apt-repository 'deb [arch=amd64,arm64,ppc64el,s390x] https://mirrors.xtom.com.hk/mariadb/repo/10.7/ubuntu focal main'
sudo apt update
sudo apt install mariadb-server
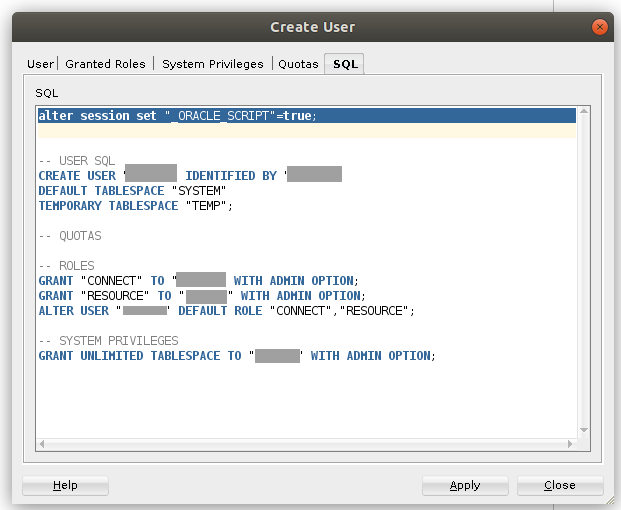
ALTER USER 'root'@'localhost' IDENTIFIED BY 'wong2903';
CREATE USER 'phpmyadmin'@'localhost' IDENTIFIED BY 'wong2903';
GRANT SELECT, INSERT, UPDATE, DELETE ON phpmyadmin.* TO 'phpmyadmin'@'localhost';
6. PHP + Nginx
sudo apt install php php-cli php-fpm php-json php-common php-mysql php-zip php-gd php-mbstring php-curl php-xml php-pear php-bcmath
sudo apt install nginx php-curl php-gd php-intl php-mbstring php-soap php-xml php-xmlrpc php-zip
See nginx.conf and site-available/default
7. Certbot
mkdir -p .xxxxx
touch .xxxxx/cloudflare.ini
chmod 600 .xxxxx/cloudflare.ini
sudo snap install core; sudo snap refresh core
sudo snap install --classic certbot
sudo snap set certbot trust-plugin-with-root=ok
sudo snap install certbot-dns-cloudflare
sudo certbot run --dns-cloudflare --dns-cloudflare-credentials ~/.xxxxx/cloudflare.ini -d *.jimmysyss.com -d jimmysyss.com -i nginx
8. PHPMyAdmin
# Create a symlink in /var/www/html to use phpmyadmin
sudo apt-get --no-install-recommends install phpmyadmin
sudo mkdir /var/www/html/phpmyadmin
sudo ln -s /usr/share/phpmyadmin phpmyadmin
In PHPMyAdmin, create a new user phpmyadmin with schema, and then select that schema, Operation, create configuration.
9. Wireguard with Algo VPN
git clone https://github.com/trailofbits/algo.git
sudo apt install -y --no-install-recommends python3-virtualenv
cd algo
python3 -m virtualenv --python="$(command -v python3)" .env &&
source .env/bin/activate &&
python3 -m pip install -U pip virtualenv &&
python3 -m pip install -r requirements.txt
10. PostgreSQL
# Create the file repository configuration:
sudo sh -c 'echo "deb http://apt.postgresql.org/pub/repos/apt $(lsb_release -cs)-pgdg main" > /etc/apt/sources.list.d/pgdg.list'
# Import the repository signing key:
wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc | sudo apt-key add -
# Update the package lists:
sudo apt-get update
# Install the latest version of PostgreSQL.
# If you want a specific version, use 'postgresql-12' or similar instead of 'postgresql':
sudo apt-get -y install postgresql
curl -L https://packagecloud.io/timescale/timescaledb/gpgkey | sudo apt-key add -
sudo sh -c "echo 'deb https://packagecloud.io/timescale/timescaledb/debian/ $(lsb_release -c -s) main' > /etc/apt/sources.list.d/timescaledb.list"
wget --quiet -O - https://packagecloud.io/timescale/timescaledb/gpgkey | sudo apt-key add -
sudo apt update
apt install timescaledb-2-postgresql-14
11. Docker
sudo apt-get install ca-certificates curl gnupg lsb-release
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io
sudo usermod -aG docker $USER