I have done some research on CockroachDB recently which make me understand a new class of database called NewSQL.
NewSQL has a few key features which is very attractive, especially we are SQL developers. Corresponding solution in GCP CloudSpanner and AWS Aurora.
1. ACID compliance, but with global locking trade-off
2. Auto-recovery and auto-rebalance under node failure
3. Global Distributed database with localized access of data
4. No phantom read, which maintain global consistency
It sounds pretty attractive in the first view. However, it must be carefully designed in order to enjoy the benefits. Let’s look at how it works first.
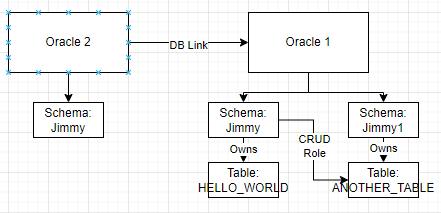
0. Define your database cluster topology, which you may define the running instance with Tags, like Region, AZ(AWS Terms), Data Center and Country. These information is useful for locating the table data and index.
1. Each Table will be partitioned by field in columns. The partitioning of data can be done with ENUM for discrete data or range for continous data.
2. Additional Sparse Indexes (Non-primary index) must also be designed with Partition in mind, the best design mechanism is to share the partition key with table data, and add additional fields for improve searching
3. Each Index or Data partition will map to a list of hints which will determine the location that piece of data is stored. CockroachDB will determine the final location by honoring the hints first. However, if there is no living instance which satisfies the hints, it will just pick one node that can spread across the globe.
4. CockroachDB maintains a network latency matrix internally, which keep track of the performance between any 2 nodes. It is a important input to CockroachDB to determine which data partition to update or to read.
5. Each Slice of data, which has a few replica among the living nodes, will elect a “leaseholder” based on table definition hints and usage statistic periodically. All read-write operation MUST go through the leaseholder in order to achieve global consistency and data locking. Since leaseholder is just a pointer among the partition replica, shifting leaseholder is a cheap operation and can change frequently (~10sec) to cope with the shape of traffic.
6. For READ table, the detail mechanism is shown here. The key take away is avoid global query and make the query local, for example, include part of the partition as you searching criterion. The query will route to the leaseholder to process, and the primary concern is the latency between the gateway node and the leaseholder. The performance is excellent in case that everything happens locally.
7. For WRITE table, the detail mechanism is shown here. The key performance trick is the location of majority update. For example, given a 3 replica environment, the leaseholder has to commit 2 out of 3 in order to declare the update is successful, therefore, the delay is related to the 2nd closest replica network latency to the leaseholder.
8. In case of node failure and recovery needed, CockroachDB is doing a great job. It will regenerate the replica at a node that trying to satisfy the hints. Since there are live replica, the performance hits are minimal, and it can self heal when a new instance comes online
9. The DDL and partition configuration can be changed by DDL, Cockroach will help to migrate the slice based on partition hints.
Base on the implementation above, there are some pitfalls which you may keep an eye on.
1. Database topology designs may require some regions clustered together and try to place data locally.
2. Data and Index has to be partitioned seperately, we should put them as closed as possible to make read-write operation localized.
3. Data is committed when majority of partitions report committed to the Leaseholder. It means you need to place the partition wisely and strike a balance between 1) majority of partitions are placed on node which are closed to each others. 2) data must be placed wide apart so that it can archieve Regional replication
4. Average latency measurement
Same City – ~5ms (InterDC dedicated line / AZ)
Same Country, Inter city – ~20ms
Cross Country, e.g. HK-SG – ~50ms
Cross Continenet, e.g. Asia vs EMEA vs US – ~200ms
Base on the latencies, we should be able to precisely predict the expected performance of individual query or operation.
HAPPY CODING!