
Every people talks about Machine Learning, Artificial Intelligence, Big Data and Data Analysis after Alpha Go launched. It is one of the hot topic recently, but seems not so many people really knows how to use it.
In general, classical AI are just solving the following problems, nothing more than that. It looks like a statistic problem rather than solving an algorithm problem.
1. Supervised Learning
a. Classification
b. Regression
2. Unsupervised Learning
a. Clustering
Supervised learning means we know the training data result, the algorithm is helping us to predict an result statistically given some an unseen data.
Unsupervised learning means we are digging gold from garbage. We don’t know the expected result. A classical example is I am given a list of personal information, try to group them in 4 categories, where 4 is defined by the algorithm users.
Classification and Regression are two key usage for supervised learning. We are solving the questions “Given your previous experience (Training Data), what is the expected value of the unseen value?” Classification is just the discrete form of regression, of course, there are many algorithm like Decision Tree only works on discrete data.
The following picture is from scikit-learn which is a Python library commonly used for Data Analysis and Machine Learning, it has a MindMap for us to determine the algorithm to be used.
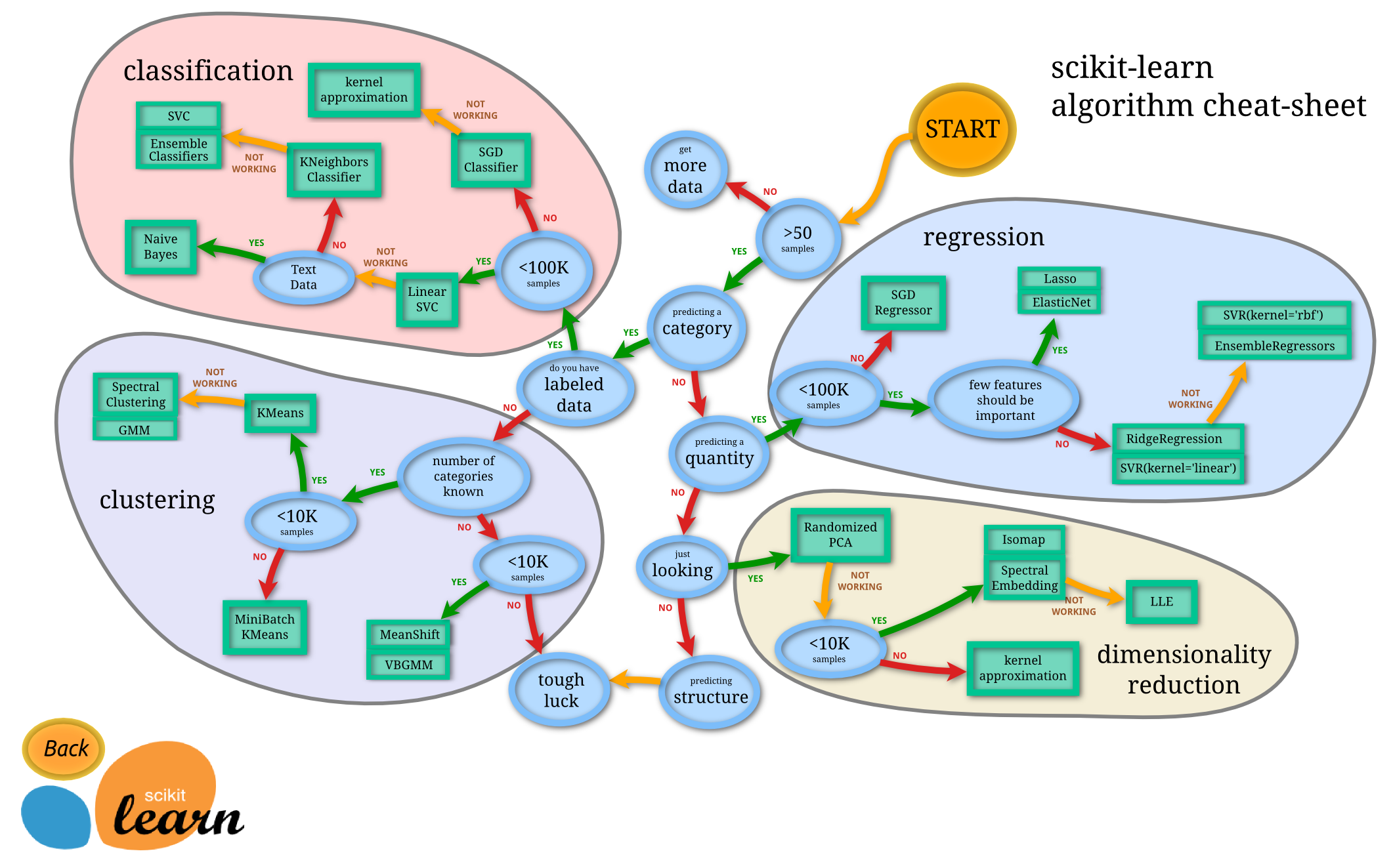
After understanding what question we are solving, the next question is obviously HOW.
We have a “pipeline” concept in most machine learning library, it is a standardized steps for training a machine learning model. However, it is not different from the programming “Input”-“Process”-“Output” model. In the other words, it doesn’t have a magic ward.
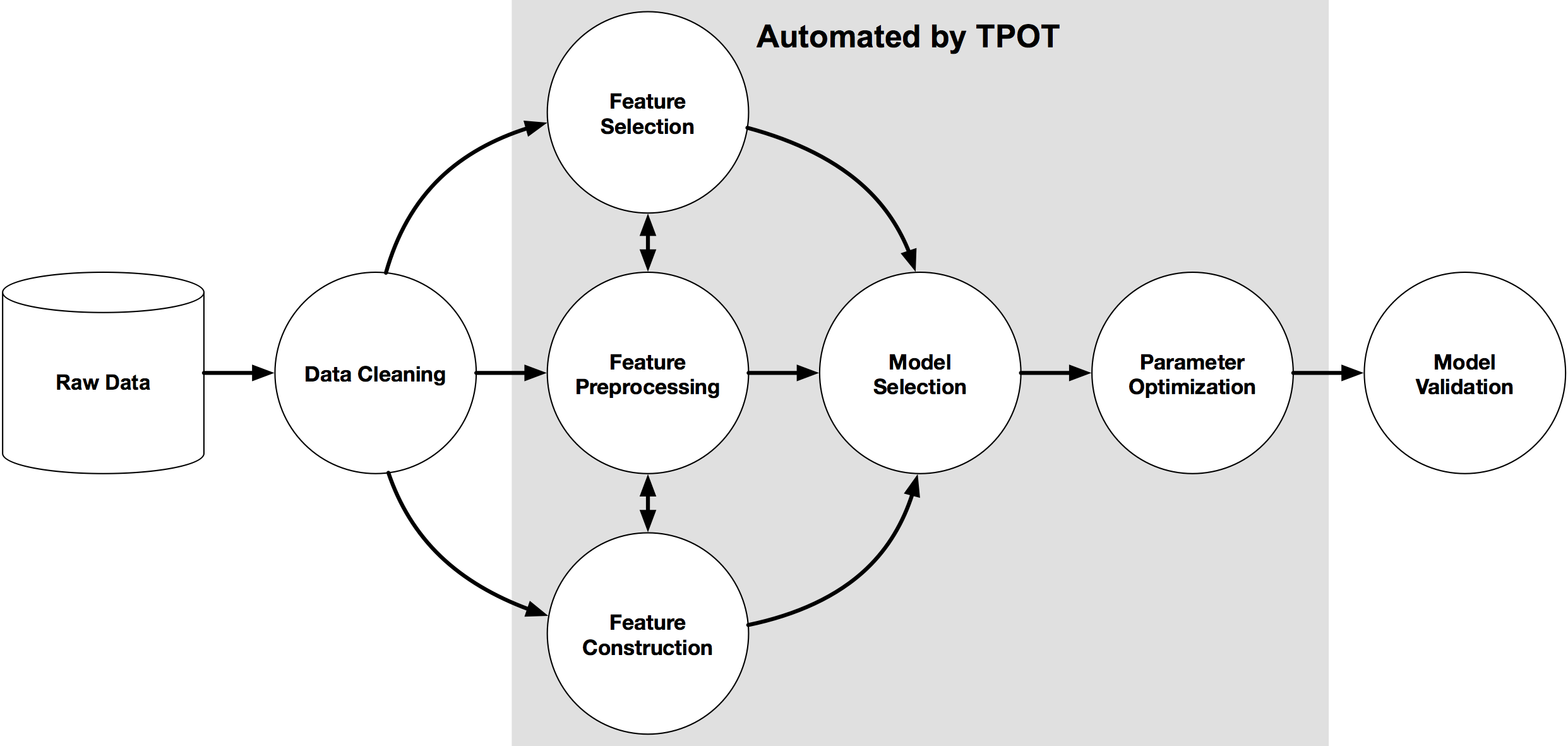
A data scientists are free to select the algorithm for each step, and linking all these steps becomes a machine learning model.